[KT에이블스쿨 5기 DX] 딥러닝 - YOLOv8
지난 게시물에 이어서 KT에이블스쿨 DX딥러닝 심화과정
실시간 YOLOv8 예복습입니당 ㅎㅎ

https://docs.ultralytics.com/models/yolov8/
YOLOv8
Explore the thrilling features of YOLOv8, the latest version of our real-time object detector! Learn how advanced architectures, pre-trained models and optimal balance between accuracy & speed make YOLOv8 the perfect choice for your object detection tasks.
docs.ultralytics.com
YOLOv8은 Ultralytics에서 개발한 YOLO(You Only Look Once) 시리즈의 최신 버전으로, 객체 탐지, 이미지 분류, 세분화, 그리고 다양한 기능을 수행하기 위한 최첨단 딥러닝 모델입니다. YOLOv8은 이전 버전인 YOLOv7, YOLOv5 등보다 향상된 성능과 효율성을 제공하여, 실시간 애플리케이션에서 강력한 도구로 사용됩니다
YOLO (You Only Look Once)는 객체 탐지를 위한 인기 있는 딥러닝 모델
이미지 내의 객체를 실시간으로 탐지하는 데 사용
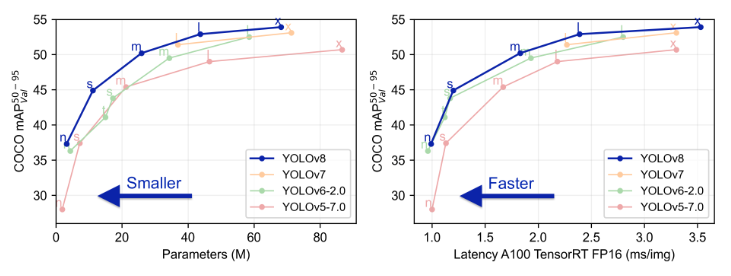
YOLOv8의 주요 특징
- 다중 객체 추적 및 계수: 비디오 프레임을 통해 여러 객체를 추적하고 정확하게 계수하는 고급 기능을 제공합니다.
- 세분화 및 자세 추정: 이미지의 상세한 분석 및 인간 자세 추정을 위한 향상된 모델을 제공합니다.
- 고성능: YOLOv8 모델은 GPU 및 CPU 환경 모두에서 탁월한 속도와 정확도를 제공합니다
- 속도: YOLO는 매우 빠른 처리 속도를 자랑하여 실시간 시스템에서 활용될 수 있습니다.
- 통합 프레임워크: 이미지를 단 한 번만 보고(You Only Look Once) 여러 객체를 탐지하며, 경계 상자(Bounding Box)와 클래스 확률을 한 번의 평가로 예측합니다.
- 일반화 성능: YOLO는 배경 오류가 적고, 새로운 환경이나 장면에 대한 일반화가 잘 되는 특성을 가지고 있습니다.
YOLOv8 사용방법
- pip을 통한 설치:
pip install ultralytics- Docker를 사용한 설치:
sudo docker pull ultralytics/ultralytics:latest
sudo docker run -it --ipc=host --gpus all ultralytics/ultralytics:latest
이 설정을 통해 YOLOv8을 독립된 컨테이너에서 실행할 수 있어 환경 관리가 간단해짐
* 코랩에서는 !를 붙여서 pip로 설치 (주의할 점 : 연결이 끊길 때마다 매번 설치를 해줘야 함)
https://docs.ultralytics.com/quickstart/
Quickstart
Explore various methods to install Ultralytics using pip, conda, git and Docker. Learn how to use Ultralytics with command line interface or within your Python projects.
docs.ultralytics.com
기본 명령어
- 이미지에서 객체 탐지를 수행:
yolo detect model=yolov8.pt source=path_to_image.jpg- 새로운 모델을 사용자의 데이터셋으로 훈련:
yolo train data=your_dataset.yaml model=yolov8n.pt epochs=10- 모델 평가:
yolo val detect data=coco.yaml device=0- 이 예제에서는 간단한 YOLOv8 훈련 및 추론 예제를 제공합니다. 이러한 모드와 기타 모드에 대한 전체 문서는 예측, 훈련, Val 및 내보내기 문서 페이지를 참조하세요. 아래 예는 객체 감지를 위한 YOLOv8 감지 모델에 대한 것입니다.
from ultralytics import YOLO
# Load a COCO-pretrained YOLOv8n model
model = YOLO('yolov8n.pt')
# Display model information (optional)
model.info()
# Train the model on the COCO8 example dataset for 100 epochs
results = model.train(data='coco8.yaml', epochs=100, imgsz=640)
# Run inference with the YOLOv8n model on the 'bus.jpg' image
results = model('path/to/bus.jpg')
YOLOv8에서 지원하는 작업
- 탐지, 분류, 세분화, 자세 추정 등 다양한 작업을 지원하여 여러 애플리케이션에 유연하게 사용할 수 있습니다.
YOLOv8 활용방안
- 보안 시스템: 실시간 비디오 감시를 통해 사람, 차량 등을 탐지하고 추적할 수 있습니다. YOLOv8의 빠른 처리 속도는 실시간 반응이 필요한 보안 시스템에 이상적입니다.
- 자율 주행 차량: 차량이 도로의 다른 차량, 보행자, 신호등 등을 인식하고 이해할 수 있도록 합니다. YOLOv8은 이러한 객체들을 정확하게 탐지하여 자율 주행의 안전성을 높일 수 있습니다.
- 산업 자동화: 제조 라인에서 제품 검사를 자동화하여 결함 있는 제품을 식별하고 분류할 수 있습니다. YOLOv8은 빠른 이미지 처리 능력을 통해 생산 효율성을 향상시킬 수 있습니다.
- 헬스케어: 의료 이미징에서 YOLOv8을 사용하여 병변, 종양 등을 탐지하고, 질병의 진단을 지원할 수 있습니다. 고해상도 이미지에서의 빠른 분석이 가능하여 의료진이 더 효과적으로 환자를 관리할 수 있도록 돕습니다.
- 소매업: 고객 행동 분석, 재고 관리, 매장 내 객체 추적 등에 사용될 수 있습니다. 예를 들어, 매장 내 고객의 움직임을 분석하여 마케팅 전략을 개선하거나 재고 부족 상황을 신속하게 파악할 수 있습니다.
Home
Explore a complete guide to Ultralytics YOLOv8, a high-speed, high-accuracy object detection & image segmentation model. Installation, prediction, training tutorials and more.
docs.ultralytics.com
Ultralytics의 공식 문서에서 제공하는 다양한 리소스와 예제를 활용

YOLO의 동작 과정
- YOLO는 이미지를 SxS 그리드로 나누고, 각 그리드 셀이 객체의 중심을 포함할 책임을 가집니다. 각 그리드 셀은 B개의 바운딩 박스와 이 박스들이 특정 클래스를 포함할 확률을 예측합니다. 그 결과, 모델은 객체의 위치, 크기, 및 클래스를 동시에 예측합니다.
- 예를 들어, 이미지에 차와 개가 있다면 YOLO 모델은 이미지를 그리드로 나누고, 각 객체의 위치를 포함하는 그리드 셀에서 차와 개 각각에 대한 바운딩 박스 및 클래스 확률을 출력합니다.
YOLO의 네트워크 설계
- YOLO의 네트워크는 일반적으로 CNN(합성곱 신경망)을 기반으로 합니다. YOLOv1의 경우 GoogleNet 스타일의 네트워크를 사용했으며, 후속 버전에서는 더 발전된 형태의 CNN을 사용하여 계층적 특징을 추출하고 이를 객체 탐지에 활용합니다.
학습 방법
- YOLO의 학습은 전체 이미지와 해당 이미지에 대한 레이블(객체의 클래스와 바운딩 박스 좌표)을 사용합니다. 대규모 이미지 데이터셋(예: COCO, PASCAL VOC)에서 사전 학습된 모델을 미세 조정하는 방식으로 진행됩니다.
손실 함수
- YOLO의 손실 함수는 세 부분으로 구성됩니다:
- 바운딩 박스 좌표에 대한 손실: 바운딩 박스의 중심 좌표 및 너비/높이에 대한 오차를 줄입니다.
- 객체 신뢰도 손실: 바운딩 박스가 객체를 포함할 확률(신뢰도)에 대한 오차를 줄입니다.
- 클래스 예측 손실: 각 그리드 셀에서 예측된 클래스 레이블의 정확성을 높입니다.
이 손실 함수를 최소화하여, 모델이 이미지에서 객체의 위치와 클래스를 더 정확하게 탐지하도록 학습합니다. YOLO는 이러한 방법으로 빠른 속도와 높은 정확도를 동시에 달성하여 많은 컴퓨터YOLO (You Only Look Once)는 컴퓨터 비전 분야에서 널리 사용되는 객체 탐지 모델입니다. 이 모델은 이미지를 한 번만 보고 여러 객체를 탐지하고 분류하는 능력을 갖추고 있어, 실시간 처리에 매우 적합합니다.
'KT에이블스쿨 5기 > DX컨설턴트' 카테고리의 다른 글
| [KT에이블스쿨 5기 DX] 주피터랩/코랩 시각화 한글 깨짐 해결 방법 (0) | 2024.04.23 |
|---|---|
| 머신러닝/딥러닝을 이용한 데이터분석 프로젝트 프로세스 (2) | 2024.04.22 |
| [KT에이블스쿨 5기 DX] 딥러닝 - Object Detection 주요 개념 (0) | 2024.04.16 |
| IT기술과 비즈니스의 연결다리 DX 컨설턴트(Digital Transformation Consultant)란? (0) | 2024.04.10 |
| 프로젝트 성공을 위한 필수 요소 '도메인지식' , 그리고 중요성 (0) | 2024.04.10 |